
The rapid advancement of artificial intelligence (AI) has revolutionized countless industries, but its potential is often hindered by the critical challenge of data privacy. Traditional AI models rely on vast amounts of real-world data, which often contains sensitive personal information. This raises significant ethical and legal concerns, limiting the scope and impact of AI applications.
Overview of the synthetic data
Synthetic data is generated data that mimics real-world data while preserving privacy. It is a powerful tool for addressing the challenges posed by using real-world data in AI development, such as data scarcity, privacy concerns, and data quality issues. By creating synthetic datasets, organizations can train AI models without compromising sensitive information.
The features of synthetic data
Learn more: Mastering Data Governance: Unleashing The Power Of AI In Business
Types of Synthetic Data
Generated from statistical models:
This type of synthetic data is created by applying statistical models to real-world data to capture its underlying patterns and distributions. Common techniques include Gaussian Mixture Models, Generative Adversarial Networks (GANs), and Variational Autoencoders (VAEs).
Rule-Based Synthetic Data:
This approach involves defining explicit rules and constraints to generate synthetic data. It is often used for structured data, like tabular data, where business rules or domain knowledge can be applied to create realistic synthetic records.
Hybrid Synthetic Data:
Combining statistical and rule-based methods to generate synthetic data that captures both statistical patterns and domain-specific knowledge. This approach can be effective for complex datasets with both structured and unstructured components.
Synthetic Data Generation from Real-World Data:
This method involves anonymizing or obfuscating real-world data to create synthetic data while preserving its utility. Techniques like differential privacy and data perturbation can be employed to protect sensitive information.
How Synthetic Data is Generated
1. Generative models and algorithms (e.g. GANs, VAEs)
Synthetic data is created using advanced techniques like generative adversarial networks (GANs) and variational autoencoders (VAEs). These models learn from real-world data and then generate new, artificial data that looks like the original.
GANs do this by having two networks—one that creates data and another that checks if it’s real or fake—work together to improve the quality of the synthetic data.
VAEs take a different approach by compressing real data and then generating new data from this compressed form. Both methods help produce realistic synthetic data that can be used for AI training.
2. Data augmentation techniques
Data augmentation is a simpler way to create synthetic data by tweaking existing data. For example, you might rotate, flip, or change an image to create a new version of it. This helps to increase the amount of data available for training AI models without needing to collect more real-world data. It’s useful in fields like image recognition and natural language processing, where small variations can improve the performance of AI systems.
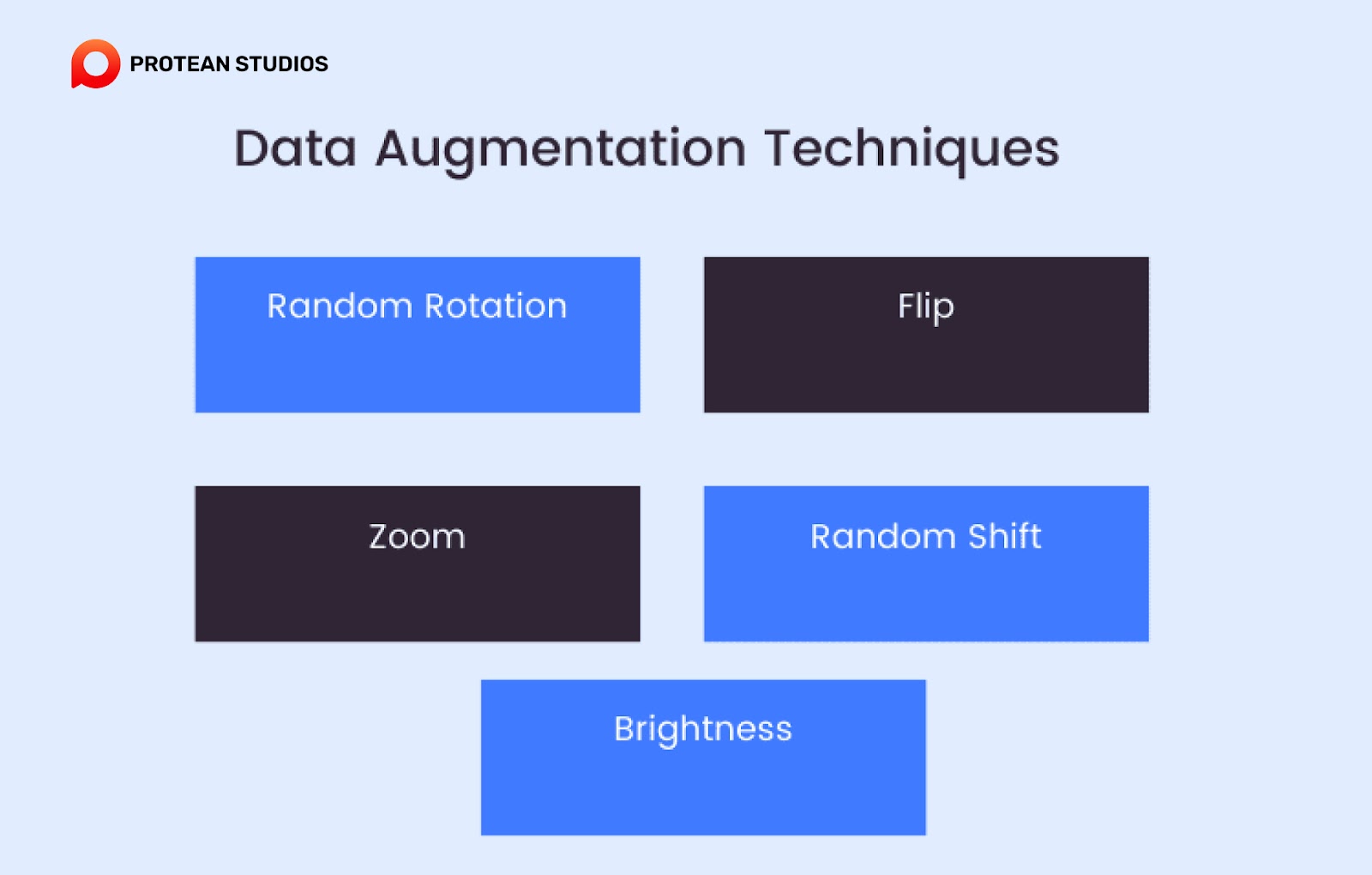
Data augmentation techniques to create synthetic data
3. Simulation-based generation
Sometimes, synthetic data is generated through simulations. This means creating a virtual environment that mimics real-world conditions and then running tests or experiments to produce data. For instance, in the development of self-driving cars, companies use simulations to create driving scenarios that the AI can learn from, such as different weather conditions or traffic situations. This approach is handy when collecting real data is too difficult or expensive.
Read more: Unveiling Generative AI: Exploring Its Power And Potential
4. Key considerations in the generation process
When generating synthetic data, there are a few important things to keep in mind:
Accuracy: The synthetic data should match the patterns and relationships found in real data.
Diversity: It’s important to generate data that covers a wide range of situations to help the AI learn more effectively.
Privacy: Synthetic data should be created in a way that doesn’t expose sensitive information from the original data.
Quality: The synthetic data must be tested and validated to ensure it’s good enough for the intended use.
Future trends and developments
1. Advances in Generative Models
Generative models like GANs and VAEs are improving, making it possible to create synthetic data that’s identical to real data. These advancements will lead to faster, more efficient models that can produce larger and more complex datasets. This progress will enable AI systems to train on high-quality synthetic data, especially in areas where real data is hard to get.
2. Increasing Adoption Across Industries
More industries are starting to use synthetic data as they see its benefits. Healthcare, finance, automotive, and retail sectors are leading the way. For example, synthetic data can help train AI in healthcare without risking patient privacy or create realistic financial market scenarios for testing. As its value becomes clear, synthetic data will become a standard tool across many fields.

The future and trends of synthetic data
3. The Role of Synthetic Data in AI and Big Data
Synthetic data is becoming essential for AI and big data projects. As AI models need more diverse and unbiased data, synthetic data provides a solution, helping to improve the accuracy and fairness of these models. In big data, synthetic datasets can simulate complex scenarios, offering better insights and decision-making tools.
Other Article: Revitalizing Marketing Automation With Generative AI: Real Deal Or Just Hype?
4. Impact on Data Governance and Policy-Making
The rise of synthetic data will influence data governance and policy. New standards and regulations will emerge to guide its ethical use, addressing concerns like privacy, accuracy, and ownership. Synthetic data could also help policymakers by providing more varied datasets, leading to better-informed decisions. As synthetic data becomes more common, it will reshape how data is managed and regulated.
In conclusion, synthetic data emerges as a powerful and promising solution to the complex interplay between AI advancement and data privacy. By generating artificial data that mirrors real-world patterns without compromising sensitive information, it offers a pathway to developing AI models.
Through careful consideration of data quality, privacy preservation techniques, and the appropriate synthetic data generation method, organizations can harness the potential of AI while mitigating privacy risks. As the field continues to evolve, ongoing research and development will be crucial in refining synthetic data methodologies and expanding their applicability across various domains.


